E-Commerce Intelligence
Why near-perfect conversion models mostly retell the basket
Rebuilt on real shop data: the near-perfect conversion AUC is largely a foregone conclusion. What matters in operations is the honest early prediction, not the headline figure from the end of the session.
The same number shows up regularly on sales slides: a model that predicts a session's purchase probability with a ROC-AUC close to perfection. We rebuilt that on real shop data and reproduced the high number. But it is largely a foregone conclusion, and that is what decides whether such a model is worth anything in operation.
1 · The data basis and a caveat that frames everything
The basis is the Data Mining Cup 2013 dataset, anonymised real data from an online shop with around 50,000 sessions and 429,000 click records. For each session it is recorded whether an order was placed in the end. Two things matter up front so that nobody reads the numbers wrong:
First, this is not a fashion dataset. The task description speaks of a general online shop with no industry. This article is therefore a general e-commerce study whose methodology transfers to any session-based shop.
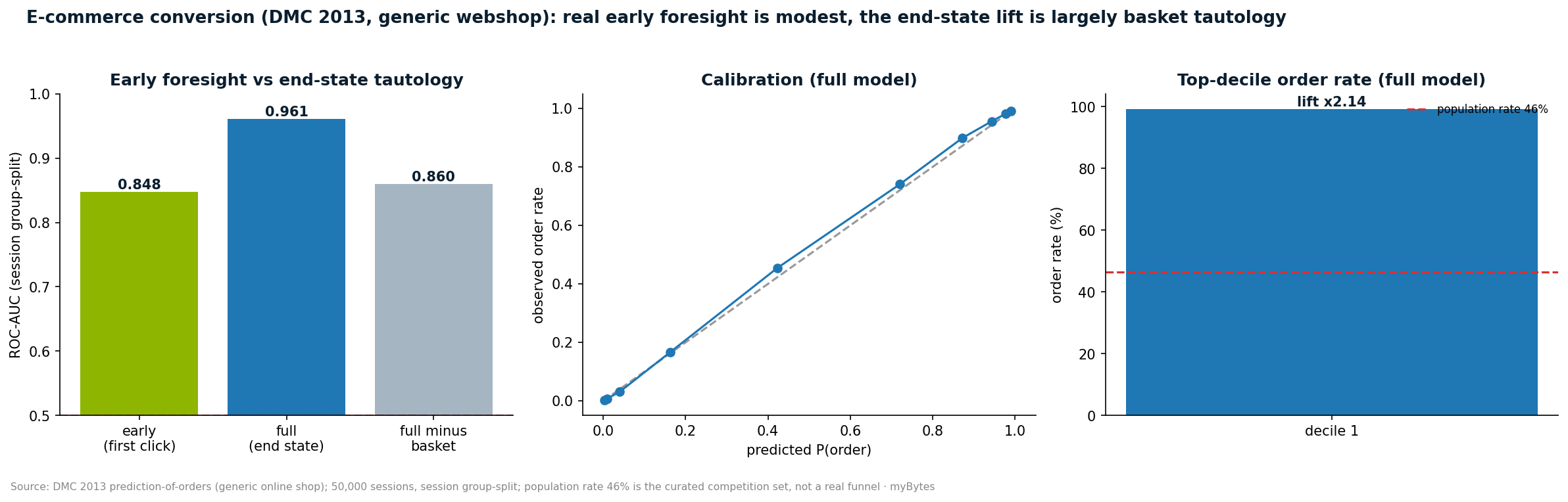
Second, and this is the most common fallacy: the order rate in the dataset is 46 percent. That is not a real funnel conversion. Real online shops convert in the low single-digit percentage range. The 46 percent are a curated competition population already containing heavily pre-filtered sessions. Whoever cites this number as a conversion benchmark is comparing apples with a competition selection.
2 · The leakage trap that produces the beautiful number
A session consists of many click records that all carry the same session label. Whoever splits randomly or row-wise into training and test has the same session on both sides. The model then memorises the answer. The only clean cut is one along the sessions, not along the rows. We split by session number: the older 80 percent into training, the newer 20 percent into the test set.
Even then the impressive number appears at first. A gradient-boosting model on the session's end state reaches an AUC of 0.961. The catch sits in the basket features. At the end of a session, the state of the basket almost gives away whether an order was placed. Remove the basket block from the features and the same prediction drops to an AUC of 0.860. A good ten AUC points of the headline figure are therefore not foresight, but a restatement of the result.
3 · What is actually actionable
What matters for operations is not the prediction at session end, but the early prediction: what can already be said after the first interaction, at a point when an intervention, say a nudge or a voucher, can still change something? This is exactly where the honest number sits. A model on the first transaction of a session alone reaches an AUC of 0.848. That is solid and usable, and it is almost level with the full model without the basket block.
The message to decision-makers is therefore clear: the number you plan an intervention on is the 0.85 of the early prediction, not the 0.96 from the end of the session. The latter is pretty on the slide and worthless in operation, because it is only certain once the customer's decision has already been made.
4 · The strongest counter-position
The strongest rebuttal: the late, basket-driven prediction has a use too, for instance to accompany an almost finished order with a cross-selling suggestion or to rescue a stalled checkout. That is true, and that is why we do not discard the full model. The point is a different one: you must not sell the basket-driven AUC as evidence of early warning. Two different tasks, two different numbers, two different intervention points.
5 · What this article does not cover
We deliberately name no euro saving. The dataset contains no clean anchor for margin or order value, and an invented number would be exactly the dishonest step this article criticises. We report predictive quality and the leakage gap, not a constructed business benefit. Beyond that: a single, anonymised shop; a competition population instead of a real funnel; and no causal model of the intervention.
Reproducibility
All figures stem from the public DMC 2013 dataset via the scripts and the notebook in the companion repository
ecommerce-conversion-prediction.
The raw data is not shipped for licensing reasons, but reproduced via a loader from the Kaggle download.
Notice
This is not legal or business consulting, but a methodological research state on a public dataset (research date: June 2026). The order rate of the dataset is a competition artefact and not a transferable conversion benchmark; metrics and assumptions should be checked against your own figures before any operational decision.Sources
- Data Mining Cup 2013, task "Prediction of orders" (prudsys): scenario, session and order definitions, tasks 1 and 2 (task PDF in the dataset).
- Data basis: Data Mining Cup 2013, public Kaggle mirror (
oscarm524/prediction-of-orders).