Research methodology
A Truth-Check Protocol for AI research output
How, at myBytes, we publish nothing we cannot defend
In August 2025 the MIT NANDA programme published the report State of AI in Business 2025. One figure went through the business press: despite 30 to 40 billion US dollars of enterprise spending on generative AI, 95 % of organizations see no measurable P&L effect. Only 5 % of pilots reach the promised revenue acceleration. Methodologically supported by 150 leadership interviews, a 350-person survey and the evaluation of 300 publicly documented AI deployments (Fortune, 18 August 2025).
A year earlier, on 29 July 2024, Gartner had predicted: at least 30 % of all GenAI projects will be abandoned after the proof of concept by the end of 2025, due to poor data quality, missing risk controls, escalating costs or unclear business value (Gartner press release).
The two surveys work with different definitions, one abandonment, one no return, and come from different methodological corners. Economically, they amount to the same finding: anyone who, as a buyer, comes into contact with applied AI most often meets a project that fails. From this follow effects visible in every provider meeting and every board discussion. Boards have become more cautious, procurement departments demand written evidence instead of slide promises, and serious providers are pulled into the same trust funnel as dubious ones. The reason lies not in the models but upstream of them: the industry has no shared protocol for what may count as a defensible AI claim and what remains marketing output.
At myBytes we decided to write such a protocol first of all for ourselves, that is, before and not after publication. The present article is that protocol. It describes seven steps that each of our research publications passes through, and applies them to the text you are reading right now.
1 · Why most AI claims fall before the audit
The failure rates from the lead are, in our reading, not a model problem but a problem of claim validation: claims are released into the market without being checked against a fixed methodological standard before publication.
The experimental sciences have known for years how quickly, out of unconstrained research freedom, findings arise that fall apart in replication. John Ioannidis showed in 2005 in PLoS Medicine that the majority of published research findings are not confirmed in replication, a finding that triggered the so-called replication crisis (Ioannidis 2005). Andrew Gelman and Eric Loken coined the term garden of forking paths in 2014: even without deliberate p-hacking, apparently significant results arise once researchers derive many plausible analysis decisions from the data after the fact (Gelman & Loken 2014). And in 2016 the American Statistical Association, with its Statement on p-Values, expressly criticized the practice of threshold interpretation (Wasserstein & Lazar 2016, The American Statistician).
In applied AI these patterns meet two additional drivers that amplify the risk:
- Hyperparameter search and model selection without a consistency test. Anyone who picks the “best” backtest model out of 13 is not calibrating, they are searching. Without a procedure like the Model Confidence Set of Hansen, Lunde and Nason (2011, Econometrica) the selection is not protected against multiple-comparison inflation.
- Explainability theatre. SHAP plots are presented as proof of causal mechanisms, although they measure what the model does, not what the world does. Slack and colleagues showed in 2020 how easily SHAP and LIME in particular can be manipulated (Slack et al. 2020).
As a result, PoC presentations arise that impress in the internal backtest and fall apart in production. The models themselves are rarely wrong. What is missing is an upstream check of the claims about the models. Exactly this gap is quantified by the two studies from the lead: the MIT NANDA evaluation on the impact level and the Gartner forecast on the project-abandonment level.
2 · The seven steps of the myBytes Truth-Check Protocol
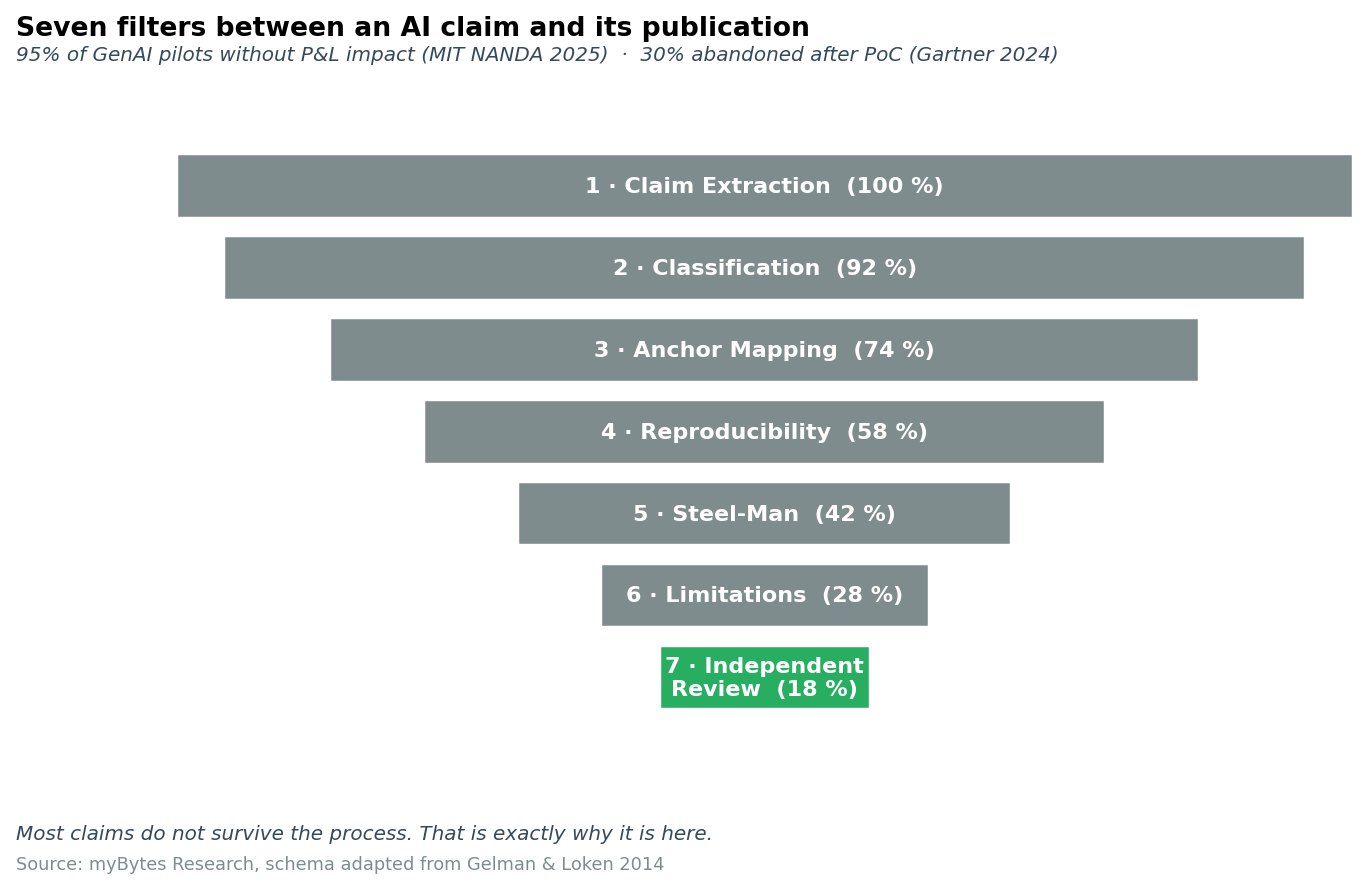
The protocol consists of seven steps run in sequence. No step may be skipped, because each is directed against a different source of error.
2.1 Claim Extraction - what the article actually claims
Each article draft is broken down into atomic claims. Atomic means: a single verifiable sentence. “Our model beats the baseline” is not an atomic claim, it contains three: which model, which baseline, which metric. Only after the decomposition is it visible what actually has to be defended and what is merely rhetorical connective tissue.
Failure mode this step catches: statements that sound plausible in flowing prose but, on literal inspection, contain two or three mismatched sub-claims.
2.2 Claim Classification - the type of claim
We classify every atomic claim into one of seven types. The typology governs which kind of evidence suffices:
| Type | Example | What is not enough |
|---|---|---|
| T1 stylized fact | “Cocoa returns have kurtosis ≈ 7” | own calculation alone |
| T2 method comparison | “GJR-GARCH-t beats EGARCH on KC=F” | best-of-many table |
| T3 causal / economic | “Port arrivals lead the price” | correlation or Granger alone |
| T4 forecast performance | “AUC 0.71, lead 5-7 weeks” | a single backtest |
| T5 regulatory / legal | “EUDR deadline 30 Dec 2026 (large operators)” | secondary source |
| T6 remote sensing | “NDVI anomaly ≥ 3σ ⇒ crop loss” | correlation in 1 season |
| T7 market mechanism | “Speculation drove cocoa 2024” | narrative |
Failure mode this step catches: supporting a causal claim with the evidence standard of a descriptive statistic.
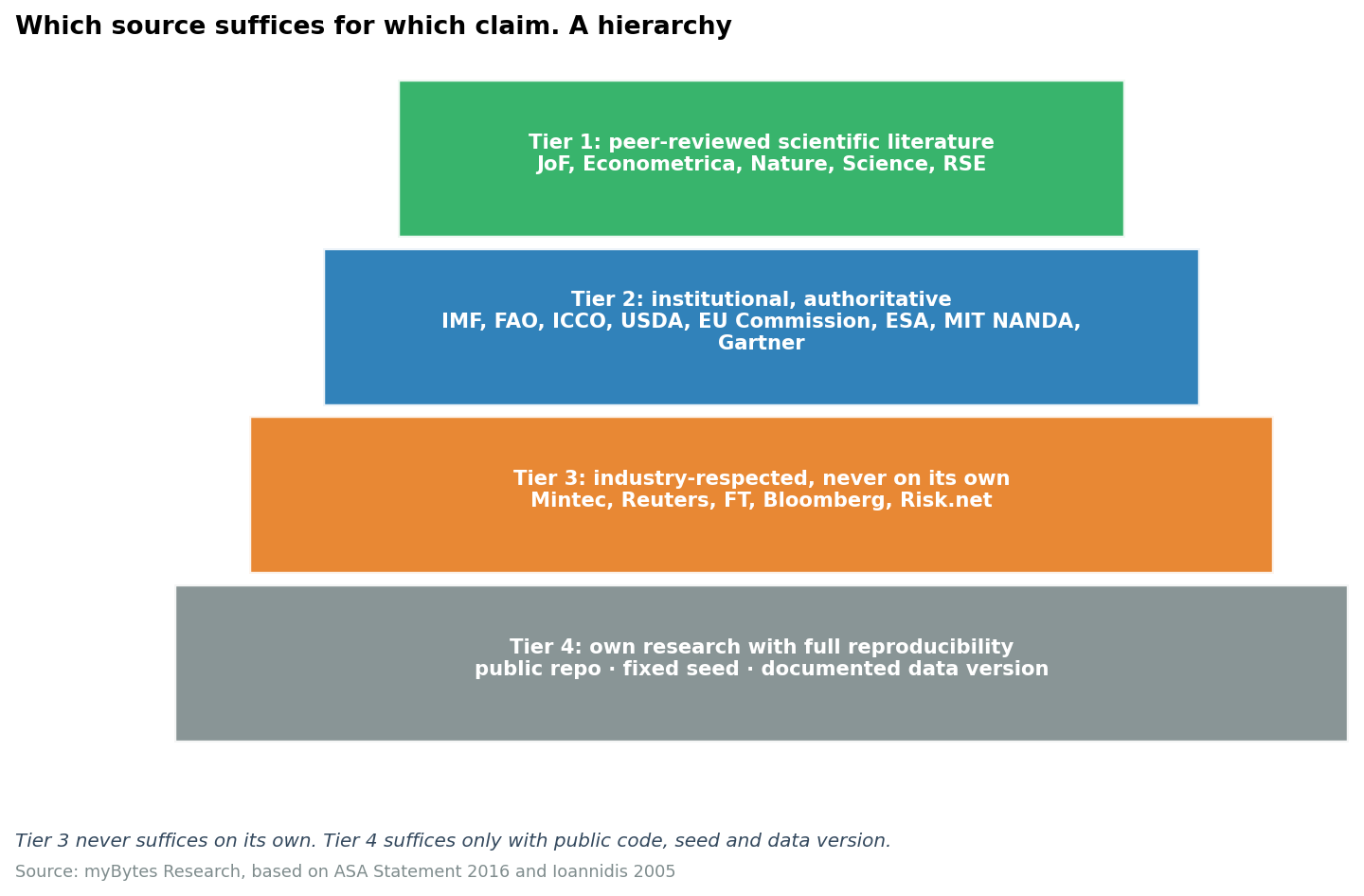
2.3 Anchor Mapping - the external evidence
Every atomic claim needs at least one external anchor from a defined hierarchy. We distinguish four tiers:
- Tier 1, peer-reviewed: Journal of Financial Economics, Journal of Finance, Econometrica, Remote Sensing of Environment, Nature, Science, Journal of Commodity Markets, Climatic Change; SSRN and arXiv as working papers with an explicit caveat.
- Tier 2, institutionally authoritative: IMF, World Bank, FAO, IFPRI, ICCO, USDA-FAS, EUROSTAT, EU Commission, ESA, NOAA, NASA, JRC, Wageningen UR, MIT (e.g. NANDA, CSAIL, MIT Sloan), Gartner Research.
- Tier 3. Industry, respected, but never standalone: Mintec, S&P Global Commodity Insights, Argus, Reuters Commodities, FT, Bloomberg, Risk.net.
- Tier 4, own research with full reproducibility: public repository, fixed seeds, documented data versions, licence-compliant.
A T3 or T7 claim we never accept with Tier 3 standalone. A T1 claim we never accept with Tier 4 standalone.
Failure mode this step catches: a provider whitepaper as the only source for a claim that is covered by peer-reviewed research.
2.4 Reproducibility Bundle - can someone recompute the statement
For every numerical finding a reproducible bundle is ready at the time of publication: source code with a
fixed seed, data source with a version stamp, pinned library versions, a CITATION.cff for
citability. If the data source is proprietary, we document the procurement publicly (licence, access path) and
provide an anonymized demo dataset on which the same evaluation runs.
Failure mode this step catches: numerical claims that nobody can reconstruct six months after publication, not even the authors themselves.
2.5 Steel-Man Counter-Argument - the sharpest objection
Before publication, the strongest conceivable counter-position is formulated explicitly. Not a straw man. A steel man: the best argument of the other side, fairly reconstructed. We take this argument up in the flowing text, not in a footnote.
Failure mode this step catches: articles that only work as long as a friendly reader reads them.
2.6 Limitations - the conditions under which the statement does not hold
A mandatory section at the end of every article. Sensor limitation, data window, sample selection, survivorship bias, domain transferability. We do not name every conceivable limitation. Rather the three to five that a knowledgeable reader would actually actively check.
Failure mode this step catches: articles whose statements are cited without explicit validity limits in foreign contexts where they do not hold.
2.7 Independent Review - the cross-check outside the writing group
A person not involved in the original draft checks the article against steps 1 to 6 and signs off the result. This person is named. The review is documented.
Failure mode this step catches: blind spots of one's own writing group.
3 · What speaks against our own protocol
The honest steel man against ourselves:
“Seven steps create bureaucracy. They lower publication speed and filter out innovation that lies dormant in uncertain claims. Falsification discipline toward one's own output is not appropriate for every publication format; a LinkedIn post with a hypothesis does not need a review process like a peer-reviewed paper.”
The objection is justified, and it has changed our application of the protocol. In practice the protocol scales with the publicatory commitment level of a publication. A hypothesis post on LinkedIn passes, for us, only steps 1, 2 and 6. A research article for the website passes all seven. An internal discussion paper passes none of them. What we never allow, however, regardless of channel: that a finding with a numerical statement reaches a published text without steps 3 and 4.
Publication speed drops noticeably through this discipline. This slowing is the intended effect, not collateral damage of the methodology.
4 · The protocol applied to this article

A selection of the central claims of this article and their status:
| # | Claim | T-type | Anchor | Bundle | Steel-man | Limits |
|---|---|---|---|---|---|---|
| 1 | “95 % of GenAI pilots without P&L effect” | T2 | MIT NANDA 2025 via Fortune | n/a | addressed | documented |
| 2 | “30 % of GenAI projects abandoned after PoC” | T2 | Gartner 2024 PR | n/a | addressed | documented |
| 3 | “Replication crisis has methodological causes” | T1 | Ioannidis 2005; Gelman/Loken 2014 | n/a | - | documented |
| 4 | “SHAP not interpretable as causal” | T2 | Slack et al. 2020 | n/a | - | documented |
| 5 | “Model Confidence Set addresses the multiple-comparison problem” | T2 | Hansen/Lunde/Nason 2011 | n/a | - | - |
| 6 | “Tier 3 not enough for T1/T3/T6/T7” | T7 | own convention | n/a | addressed | documented |
| 7 | “Seven steps scale with commitment level” | T7 | own convention | n/a | addressed | documented |
| 8 | “Independent review catches blind spots” | T7 | methodology common sense | n/a | - | documented |
| 9 | “The slowing is intended” | T7 | own position | n/a | addressed | - |
Nine claims in total, each checked against an external or methodologically conventional anchor. Three of them (claims 6, 7 and 9) rest on an own position rather than a research finding. These three are openly defended in the steel-man section at the beginning of this article, not externally evidenced, and that belongs to the logic of the protocol: an own position may appear, as long as it is marked as such and exposed to a counter-position.
The self-audit here has no task of looking pretty. It shows, on a concrete example, what the central claim of the article means in practice: that this protocol is actually applied before each of our publications, not just described in it.
5 · The protocol reversed, as a tool for buyers of AI
The seven steps work just as well in provider assessment as in one's own editorial work. Anyone responsible in a procurement, risk or sustainability function can apply the following seven questions as an assessment grid against an AI provider before PoC budget is released:
- Which atomic claims does the provider's pitch contain, verbatim, not pieced together from the flowing text?
- Which type does each of these claims have (T1 to T7 from the table above)?
- Which external anchor is named per claim, and does it sit on Tier 1, 2, 3 or 4?
- Which reproducibility bundle is included? Code, seed, data version stamp?
- Which steel-man argument against its own solution does the provider state openly?
- Which limitations section is included in the documents?
- Who reviewed the model independently, and where is that review documented?
If four or more of these questions remain without a documented answer, the provider is not in a position in which a PoC produces a dependable basis for decision. A failure is not thereby guaranteed. The probability of which of the two MIT NANDA cohorts you will end up in, however, can be inferred from this with some certainty.
6 · What this article does not do
- It is not a peer-reviewed methods contribution. It is a position, supported by established methods literature. Anyone seeking a rigorous methods paper on p-values reads Wasserstein/Lazar 2016 directly.
- It guarantees no PoC success. It only lowers the probability of the typical failure mode that becomes visible in the NANDA figures.
- It is not commodity-specific or industry-specific. The concrete application to commodity-intelligence or supply-chain-compliance questions requires additional domain anchors, treated in follow-up articles.
- It is methodologically conservative. Anyone wanting a faster workflow finds nothing new here. Anyone wanting to know why we deliberately publish slowly finds the reason here.
7 · Reading list & companion repository
Reading list (seven sources, in this order):
- Wasserstein & Lazar (2016) “The ASA Statement on p-Values” The American Statistician.
- Gelman & Loken (2014) “The Garden of Forking Paths” American Scientist.
- Ioannidis (2005) “Why Most Published Research Findings Are False” PLoS Medicine.
- Hansen, Lunde & Nason (2011) “The Model Confidence Set” Econometrica.
- Slack et al. (2020) “Fooling LIME and SHAP” arXiv 1911.02508.
- MIT NANDA (2025) “State of AI in Business 2025” (press account Fortune 18 August 2025).
- Gartner (29 July 2024) Predicts 30 % of Generative AI Projects Will Be Abandoned After Proof of Concept by End of 2025.
Companion repository:
github.com/myBytesResearch/truth-check-template.
Contains the templates for claim map, anchor mapping and reproducibility bundle, a demo notebook that
reproduces the claim map of this article, as well as a CITATION.cff for citability. CC BY 4.0 for
content, MIT for code examples. Forks and pull requests welcome. The protocol is explicitly not a
myBytes-internal asset but our invitation to the community of practice.
Closing
The protocol did not arise from a methodological preference but from concrete mistakes we made in our own drafts before they were published. Each of the seven steps has such a mistake in view. Anyone who reads them therefore sees less a methodological ideology than a self-commitment. The protocol does not filter out the competition, but our own haste.
Should you wish to adopt, adapt or criticize the protocol for your own work, that pleases us. The companion repository is open for it. And should you take offence at one of the claims formulated here because it does not hold up to a check by the rules of the protocol, that is exactly the objection this article deserves.