E-Commerce Intelligence
Dlaczego niemal idealne modele konwersji najczęściej opowiadają koszyk
Odtworzone na rzeczywistych danych sklepu: niemal idealne AUC konwersji jest w dużej mierze rzeczą oczywistą. W działaniu liczy się uczciwa wczesna predykcja, a nie efektowna liczba z końca sesji.
Na slajdach sprzedażowych regularnie pojawia się ta sama liczba: model, który przewiduje prawdopodobieństwo zakupu w sesji z ROC-AUC bliskim doskonałości. Odtworzyliśmy to na rzeczywistych danych sklepu i powtórzyliśmy wysoką liczbę. Jest ona jednak w dużej mierze rzeczą oczywistą, i to właśnie rozstrzyga, czy taki model jest cokolwiek wart w działaniu.
1 · Podstawa danych i zastrzeżenie, które ramuje wszystko
Podstawą jest zbiór danych Data Mining Cup 2013, zanonimizowane rzeczywiste dane sklepu internetowego z około 50 000 sesji i 429 000 rekordów kliknięć. Dla każdej sesji odnotowano, czy na końcu padło zamówienie. Dwie rzeczy są ważne na wstępie, aby nikt nie odczytał liczb błędnie:
Po pierwsze, to nie jest zbiór modowy. Opis zadania mówi o ogólnym sklepie internetowym bez branży. Ten artykuł jest więc ogólnym studium e-commerce, którego metodyka przenosi się na każdy sklep oparty na sesjach.
Po drugie, i to jest najczęstszy błąd: odsetek zamówień w zbiorze wynosi 46 procent. To nie jest rzeczywista konwersja lejka. Realne sklepy internetowe konwertują w niskim, jednocyfrowym zakresie procentowym. Te 46 procent to wyselekcjonowana populacja konkursowa, w której znajdują się już mocno wstępnie odfiltrowane sesje. Kto cytuje tę liczbę jako benchmark konwersji, porównuje jabłka z wyborem konkursowym.
2 · Pułapka wycieku danych, która wytwarza piękną liczbę
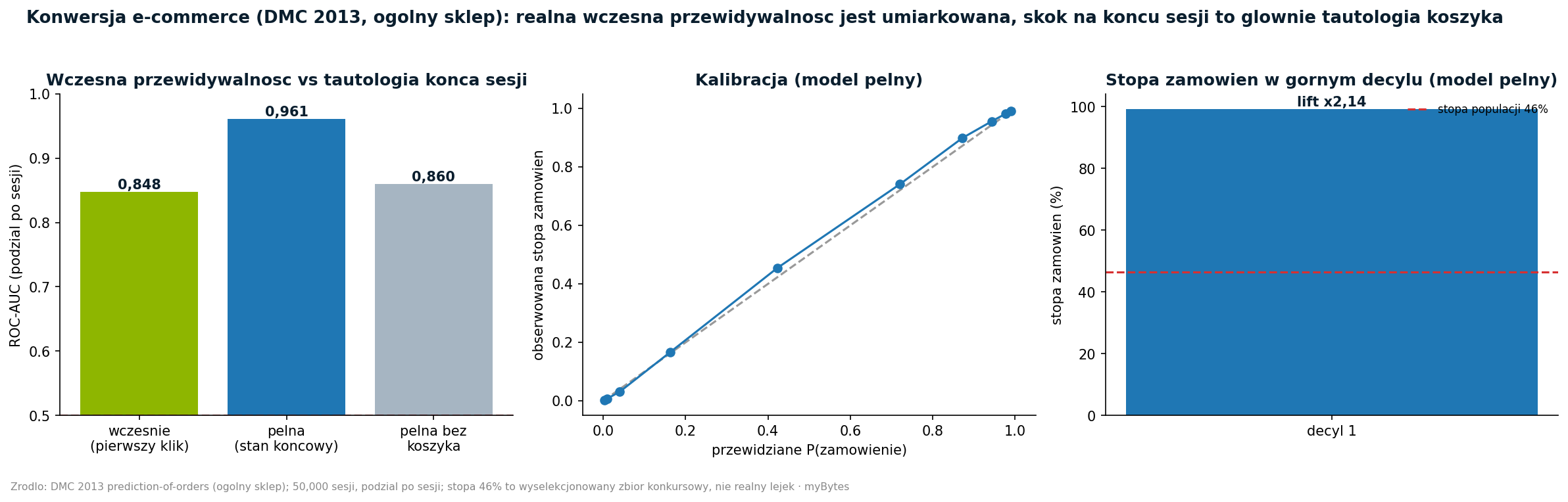
Sesja składa się z wielu rekordów kliknięć, które wszystkie noszą tę samą etykietę sesji. Kto dzieli losowo lub wierszowo na trening i test, ma tę samą sesję po obu stronach. Model uczy się wtedy odpowiedzi na pamięć. Czysty jest tylko podział wzdłuż sesji, a nie wzdłuż wierszy. Dzielimy według numeru sesji: starsze 80 procent do treningu, nowsze 20 procent do zbioru testowego.
Nawet wtedy najpierw pojawia się imponująca liczba. Model gradient boosting na stanie końcowym sesji osiąga AUC 0,961. Haczyk tkwi w cechach koszyka. Pod koniec sesji stan koszyka niemal zdradza, czy złożono zamówienie. Gdy usuniemy blok koszyka z cech, ta sama predykcja spada do AUC 0,860. Dobre dziesięć punktów AUC efektownej liczby to więc nie dalekowzroczność, lecz przeformułowanie wyniku.
3 · Co jest naprawdę wykonalne
Dla działania interesująca jest nie predykcja na końcu sesji, lecz predykcja wczesna: co da się powiedzieć już po pierwszej interakcji, w momencie, w którym interwencja, na przykład podpowiedź lub kupon, może jeszcze coś zmienić? Właśnie tu leży uczciwa liczba. Model oparty wyłącznie na pierwszej transakcji sesji osiąga AUC 0,848. To jest solidne i użyteczne, i leży niemal na równi z pełnym modelem bez bloku koszyka.
Przekaz dla decydentów jest więc jasny: liczba, na której planuje się interwencję, to 0,85 wczesnej predykcji, a nie 0,96 z końca sesji. Ta druga jest ładna na slajdzie i bezwartościowa w działaniu, ponieważ jest pewna dopiero wtedy, gdy decyzja klienta i tak już zapadła.
4 · Najmocniejsze stanowisko przeciwne
Najmocniejsza riposta: także późna, napędzana koszykiem predykcja ma swój pożytek, na przykład by towarzyszyć niemal gotowemu zamówieniu propozycją cross-sellingu lub uratować zacinający się proces płatności. To prawda i dlatego nie odrzucamy pełnego modelu. Chodzi o coś innego: nie wolno sprzedawać AUC napędzanego koszykiem jako dowodu wczesnego ostrzegania. Dwa różne zadania, dwie różne liczby, dwa różne momenty interwencji.
5 · Czego ten artykuł nie obejmuje
Świadomie nie podajemy żadnej oszczędności w euro. Zbiór danych nie zawiera czystej kotwicy dla marży ani wartości zamówienia, a wymyślona liczba byłaby dokładnie tym nieuczciwym krokiem, który ten artykuł krytykuje. Raportujemy jakość predykcji i odstęp wycieku danych, a nie skonstruowaną korzyść biznesową. Poza tym: pojedynczy, zanonimizowany sklep; populacja konkursowa zamiast realnego lejka; i brak modelu przyczynowego interwencji.
Odtwarzalność
Wszystkie liczby powstają z publicznego zbioru DMC 2013 za pomocą skryptów i notebooka w repozytorium
towarzyszącym
ecommerce-conversion-prediction.
Surowe dane nie są dołączane ze względów licencyjnych, lecz odtwarzane loaderem z pobrania z Kaggle.
Uwaga
To nie jest doradztwo prawne ani biznesowe, lecz metodyczny stan badań na publicznym zbiorze danych (stan badań: czerwiec 2026). Odsetek zamówień w zbiorze jest artefaktem konkursowym, a nie przenośnym miernikiem konwersji; wskaźniki i założenia należy przed decyzją operacyjną sprawdzić na własnych liczbach.Źródła
- Data Mining Cup 2013, zadanie „Prediction of orders" (prudsys): scenariusz, pojęcie sesji i zamówienia, zadania 1 i 2 (PDF zadania w zbiorze danych).
- Podstawa danych: Data Mining Cup 2013, publiczny mirror na Kaggle (
oscarm524/prediction-of-orders).