Metodyka badawcza
Protokół Truth-Check dla wyników badań nad AI
Jak w myBytes nie publikujemy niczego, czego nie potrafimy obronić

W sierpniu 2025 program MIT NANDA opublikował raport State of AI in Business 2025. Jedna liczba obiegła prasę gospodarczą: mimo 30 do 40 miliardów dolarów wydatków korporacyjnych na generatywne AI 95 % organizacji nie widzi mierzalnego efektu P&L. Tylko 5 % pilotaży osiąga obiecane przyspieszenie przychodów. Metodycznie oparte na 150 wywiadach z kierownictwem, ankiecie na 350 osobach i analizie 300 publicznie udokumentowanych wdrożeń AI (Fortune, 18 sierpnia 2025).
Rok wcześniej, 29 lipca 2024, Gartner prognozował: co najmniej 30 % wszystkich projektów GenAI zostanie porzuconych po proof of concept do końca 2025, z powodu słabej jakości danych, braku kontroli ryzyka, eskalujących kosztów lub niejasnej wartości biznesowej (komunikat prasowy Gartnera).
Oba badania pracują na różnych definicjach, raz porzucenie, raz brak zwrotu, i pochodzą z różnych zakątków metodycznych. Ekonomicznie sprowadzają się do tego samego wniosku: kto jako nabywca styka się ze stosowanym AI, najczęściej trafia na projekt, który zawodzi. Z tego wynikają efekty widoczne w każdej rozmowie z dostawcą i w każdej dyskusji zarządu. Zarządy stały się ostrożniejsze, działy zakupów żądają pisemnych dowodów zamiast obietnic ze slajdów, a poważni dostawcy są wciągani w ten sam lejek zaufania co niepoważni. Przyczyna leży nie w modelach, lecz przed nimi: branża nie ma wspólnego protokołu tego, co może uchodzić za obronne twierdzenie o AI, a co pozostaje wynikiem marketingowym.
W myBytes zdecydowaliśmy się napisać taki protokół najpierw dla siebie, czyli przed publikacją, a nie po niej. Niniejszy artykuł jest tym protokołem. Opisuje siedem kroków, przez które przechodzi każda z naszych publikacji badawczych, i stosuje je do tekstu, który właśnie czytasz.
1 · Dlaczego większość twierdzeń o AI upada przed audytem
Wskaźniki niepowodzeń z leadu są w naszym odczytaniu nie problemem modelu, lecz problemem walidacji twierdzeń: twierdzenia są wypuszczane na rynek bez sprawdzenia ich przed publikacją względem stałego standardu metodycznego.
Nauki eksperymentalne od lat wiedzą, jak szybko z nieograniczonej swobody badawczej powstają wyniki, które rozpadają się w replikacji. John Ioannidis wykazał w 2005 w PLoS Medicine, że większość opublikowanych wyników badań nie potwierdza się w replikacji, co wywołało tzw. kryzys replikacji (Ioannidis 2005). Andrew Gelman i Eric Loken ukuli w 2014 termin garden of forking paths: nawet bez celowego p-hackingu pozornie istotne wyniki powstają, gdy badacze wyprowadzają wiele prawdopodobnych decyzji analitycznych z danych po fakcie (Gelman & Loken 2014). A American Statistical Association w 2016 swoim Statement on p-Values wyraźnie skrytykowała praktykę interpretacji progowej (Wasserstein & Lazar 2016, The American Statistician).
W stosowanym AI te wzorce trafiają na dwa dodatkowe czynniki, które wzmacniają ryzyko:
- Przeszukiwanie hiperparametrów i wybór modelu bez testu spójności. Kto z 13 modeli wybiera „najlepszy” model backtestu, nie kalibruje, lecz szuka. Bez procedury takiej jak Model Confidence Set Hansena, Lundego i Nasona (2011, Econometrica) wybór nie jest chroniony przed inflacją wielokrotnych porównań.
- Teatr wyjaśnialności. Wykresy SHAP są przedstawiane jako dowód mechanizmów przyczynowych, choć mierzą to, co robi model, a nie to, co robi świat. Slack i współpracownicy pokazali w 2020, jak łatwo manipulować właśnie SHAP i LIME (Slack i in. 2020).
W efekcie powstają prezentacje PoC, które imponują w wewnętrznym backteście i rozpadają się w produkcji. Same modele są przy tym rzadko błędne. Brakuje wcześniejszego sprawdzenia twierdzeń o modelach. Dokładnie tę lukę kwantyfikują oba badania z leadu: analiza MIT NANDA na poziomie efektu i prognoza Gartnera na poziomie porzucania projektów.
2 · Siedem kroków protokołu Truth-Check myBytes
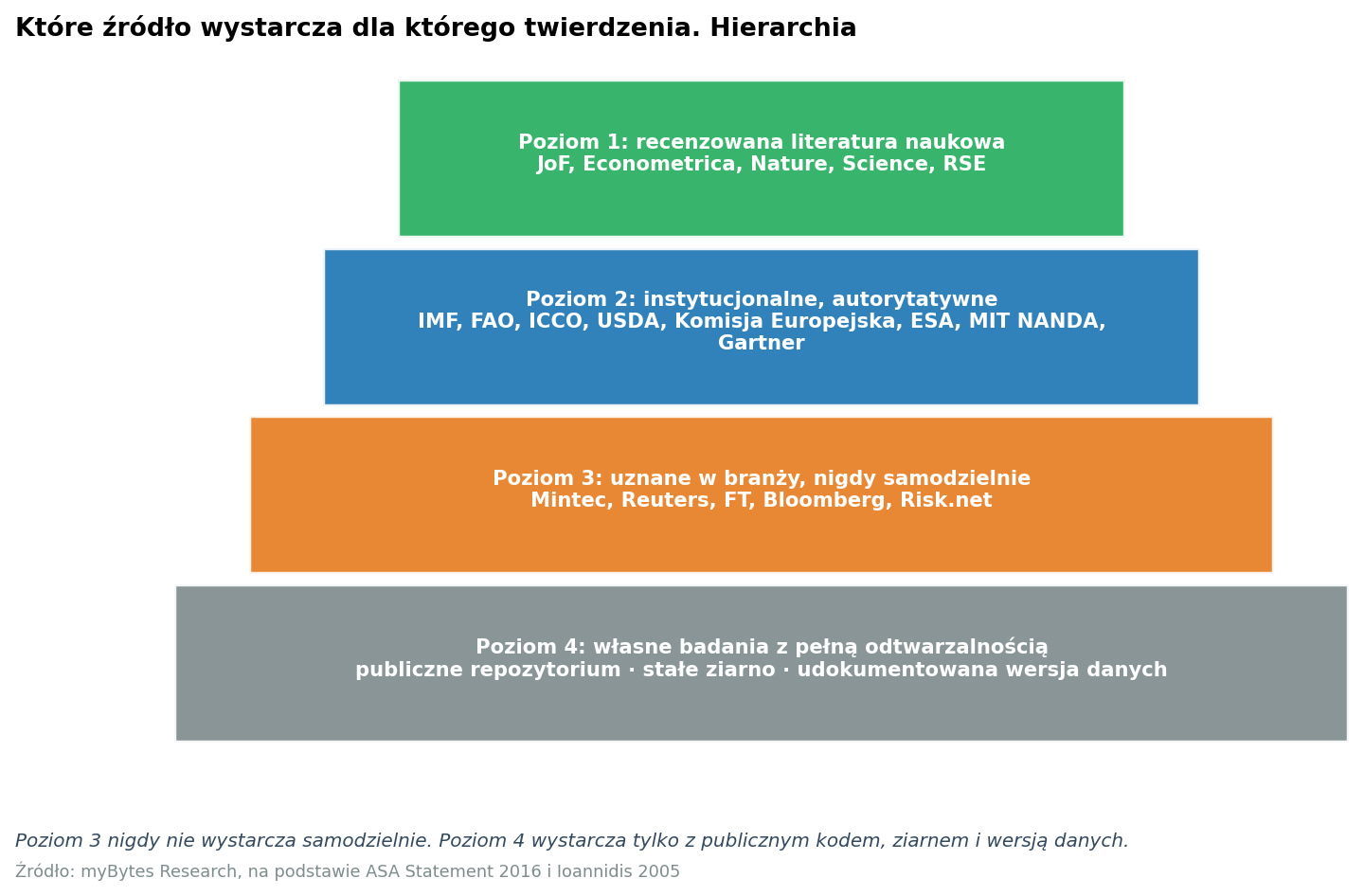
Protokół składa się z siedmiu kroków przechodzonych po kolei. Żadnego kroku nie wolno pominąć, bo każdy jest wymierzony w inne źródło błędu.
2.1 Claim Extraction - co artykuł właściwie twierdzi
Każdy szkic artykułu jest rozkładany na twierdzenia atomowe. Atomowe znaczy: pojedyncze, weryfikowalne zdanie. „Nasz model bije baseline” nie jest twierdzeniem atomowym, zawiera trzy: który model, który baseline, która metryka. Dopiero po rozkładzie widać, co faktycznie trzeba obronić, a co jest tylko retoryczną tkanką łączną.
Tryb awarii, który ten krok wyłapuje: stwierdzenia, które w ciągłym tekście brzmią prawdopodobnie, ale przy dosłownym sprawdzeniu zawierają dwa lub trzy niepasujące do siebie podtwierdzenia.
2.2 Claim Classification - typ twierdzenia
Klasyfikujemy każde twierdzenie atomowe do jednego z siedmiu typów. Typologia steruje tym, jaki rodzaj dowodu wystarcza:
| Typ | Przykład | Co nie wystarcza |
|---|---|---|
| T1 fakt stylizowany | „Stopy zwrotu kakao mają kurtozę ≈ 7” | samo własne obliczenie |
| T2 porównanie metod | „GJR-GARCH-t bije EGARCH na KC=F” | tabela „najlepszego z wielu” |
| T3 przyczynowy / ekonomiczny | „Przybycia do portu wyprzedzają cenę” | sama korelacja lub Granger |
| T4 skuteczność prognozy | „AUC 0,71, wyprzedzenie 5-7 tyg.” | jeden backtest |
| T5 regulacyjny / prawny | „Termin EUDR 30.12.2026 (duże podmioty)” | źródło wtórne |
| T6 teledetekcja | „Anomalia NDVI ≥ 3σ ⇒ utrata plonu” | korelacja w 1 sezonie |
| T7 mechanizm rynkowy | „Spekulacja napędzała kakao 2024” | narracja |
Tryb awarii, który ten krok wyłapuje: podpieranie twierdzenia przyczynowego standardem dowodowym statystyki opisowej.
2.3 Anchor Mapping - dowód zewnętrzny
Każde twierdzenie atomowe potrzebuje co najmniej jednej kotwicy zewnętrznej z określonej hierarchii. Rozróżniamy cztery poziomy (tiers):
- Tier 1, recenzowane: Journal of Financial Economics, Journal of Finance, Econometrica, Remote Sensing of Environment, Nature, Science, Journal of Commodity Markets, Climatic Change; SSRN i arXiv jako working papers z wyraźnym zastrzeżeniem.
- Tier 2, instytucjonalnie autorytatywne: IMF, Bank Światowy, FAO, IFPRI, ICCO, USDA-FAS, EUROSTAT, Komisja Europejska, ESA, NOAA, NASA, JRC, Wageningen UR, MIT (np. NANDA, CSAIL, MIT Sloan), Gartner Research.
- Tier 3. Branżowe, szanowane, ale nigdy samodzielnie: Mintec, S&P Global Commodity Insights, Argus, Reuters Commodities, FT, Bloomberg, Risk.net.
- Tier 4, badania własne z pełną odtwarzalnością: publiczne repozytorium, stałe seedy, udokumentowane wersje danych, zgodność licencyjna.
Twierdzenia T3 lub T7 nigdy nie akceptujemy z samym Tier 3. Twierdzenia T1 nigdy nie akceptujemy z samym Tier 4.
Tryb awarii, który ten krok wyłapuje: whitepaper dostawcy jako jedyne źródło twierdzenia, które jest pokryte badaniami recenzowanymi.
2.4 Reproducibility Bundle - czy ktoś może przeliczyć stwierdzenie
Dla każdego wyniku liczbowego w chwili publikacji gotowy jest odtwarzalny pakiet: kod źródłowy ze stałym
seedem, źródło danych ze znacznikiem wersji, przypięte wersje bibliotek, plik CITATION.cff dla
cytowalności. Jeśli źródło danych jest własnościowe, dokumentujemy dostęp publicznie (licencja, droga dostępu) i
udostępniamy zanonimizowany zbiór demonstracyjny, na którym działa ta sama analiza.
Tryb awarii, który ten krok wyłapuje: twierdzenia liczbowe, których pół roku po publikacji nikt już nie potrafi zrekonstruować, nawet sami autorzy.
2.5 Steel-Man Counter-Argument - najostrzejszy zarzut
Przed publikacją najsilniejsza wyobrażalna kontrpozycja jest formułowana wprost. Nie chochoł. Steel man: najlepszy argument drugiej strony, uczciwie zrekonstruowany. Podejmujemy ten argument w ciągłym tekście, nie w przypisie.
Tryb awarii, który ten krok wyłapuje: artykuły, które działają tylko dopóki czyta je przychylny czytelnik.
2.6 Limitations - warunki, w których stwierdzenie nie obowiązuje
Obowiązkowa sekcja na końcu każdego artykułu. Ograniczenie sensora, okno danych, dobór próby, bias przeżywalności, przenoszalność dziedzinowa. Nie nazywamy wszystkich wyobrażalnych ograniczeń. Lecz te trzy do pięciu, które kompetentny czytelnik rzeczywiście aktywnie by sprawdził.
Tryb awarii, który ten krok wyłapuje: artykuły, których stwierdzenia są cytowane bez wyraźnych granic ważności w obcych kontekstach, w których nie obowiązują.
2.7 Independent Review - kontrola poza grupą piszącą
Osoba, która nie brała udziału w pierwotnym szkicu, sprawdza artykuł względem kroków 1 do 6 i podpisuje wynik. Osoba ta jest wymieniona z nazwiska. Recenzja jest udokumentowana.
Tryb awarii, który ten krok wyłapuje: martwe pola własnej grupy piszącej.
3 · Co przemawia przeciw naszemu własnemu protokołowi
Uczciwy steel man przeciwko nam samym:
„Siedem kroków tworzy biurokrację. Obniżają szybkość publikacji i odfiltrowują innowację, która drzemie w niepewnych twierdzeniach. Dyscyplina falsyfikacji wobec własnych wyników nie jest odpowiednia dla każdego formatu publikacji; post na LinkedIn z hipotezą nie potrzebuje procesu recenzji jak artykuł recenzowany.”
Zarzut jest słuszny i zmienił nasze stosowanie protokołu. W praktyce protokół skaluje się ze stopniem zobowiązania publikacyjnego danej publikacji. Post hipotetyczny na LinkedIn przechodzi u nas tylko kroki 1, 2 i 6. Artykuł badawczy na stronę przechodzi wszystkie siedem. Wewnętrzny dokument dyskusyjny nie przechodzi żadnego z nich. Czego jednak nigdy nie dopuszczamy, niezależnie od kanału: by wynik z twierdzeniem liczbowym trafił do opublikowanego tekstu bez kroków 3 i 4.
Szybkość publikacji spada przez tę dyscyplinę odczuwalnie. To spowolnienie jest zamierzonym efektem, nie szkodą uboczną metodyki.
4 · Protokół zastosowany do tego artykułu
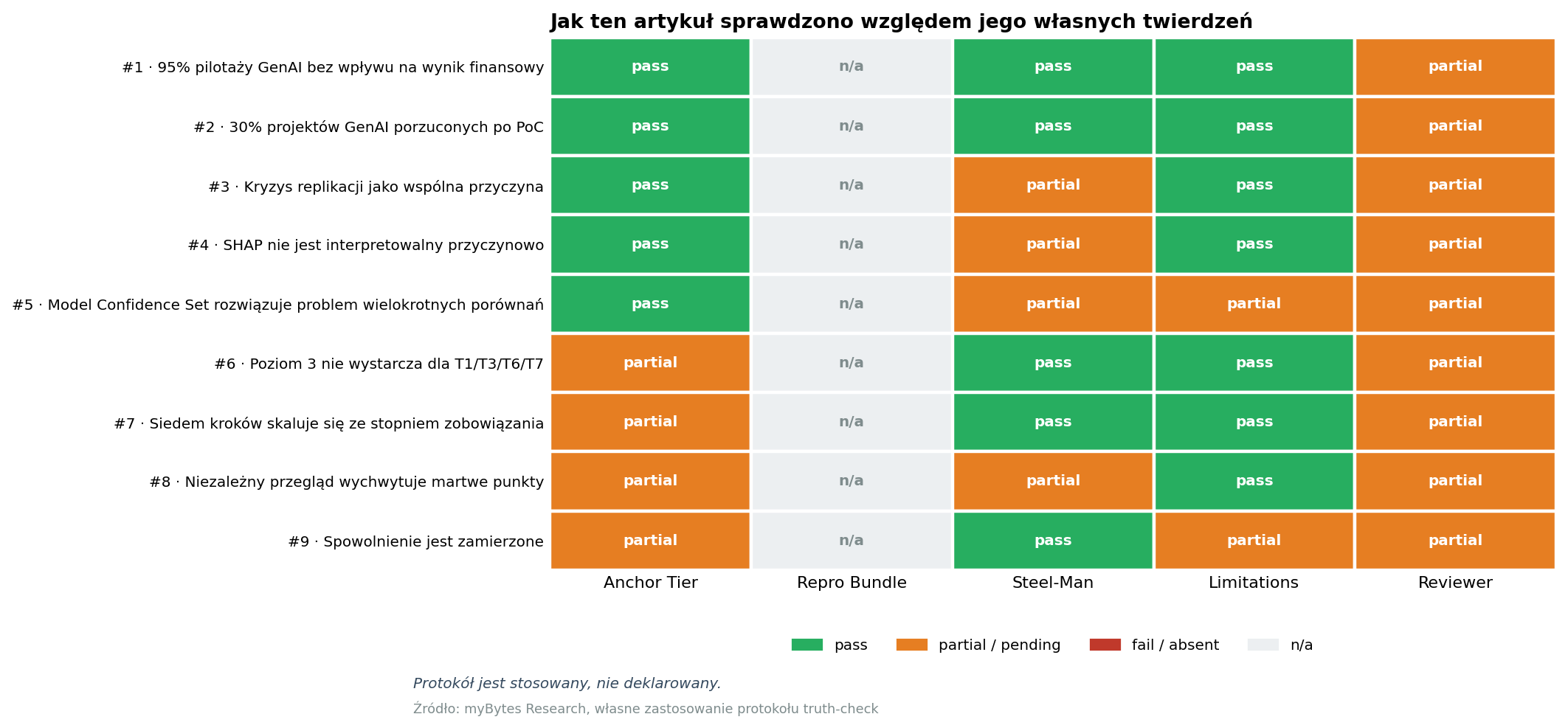
Wybór centralnych twierdzeń tego artykułu i ich status:
| # | Twierdzenie | Typ T | Kotwica | Pakiet | Steel-man | Ograniczenia |
|---|---|---|---|---|---|---|
| 1 | „95 % pilotaży GenAI bez efektu P&L” | T2 | MIT NANDA 2025 via Fortune | n/a | podjęte | udokumentowane |
| 2 | „30 % projektów GenAI porzuconych po PoC” | T2 | Gartner 2024 PR | n/a | podjęte | udokumentowane |
| 3 | „Kryzys replikacji ma przyczyny metodyczne” | T1 | Ioannidis 2005; Gelman/Loken 2014 | n/a | - | udokumentowane |
| 4 | „SHAP nie do interpretacji jako przyczynowy” | T2 | Slack i in. 2020 | n/a | - | udokumentowane |
| 5 | „Model Confidence Set rozwiązuje problem wielokrotnych porównań” | T2 | Hansen/Lunde/Nason 2011 | n/a | - | - |
| 6 | „Tier 3 nie wystarcza dla T1/T3/T6/T7” | T7 | konwencja własna | n/a | podjęte | udokumentowane |
| 7 | „Siedem kroków skaluje się ze stopniem zobowiązania” | T7 | konwencja własna | n/a | podjęte | udokumentowane |
| 8 | „Niezależna recenzja wyłapuje martwe pola” | T7 | zdrowy rozsądek metodyczny | n/a | - | udokumentowane |
| 9 | „Spowolnienie jest zamierzone” | T7 | pozycja własna | n/a | podjęte | - |
Łącznie dziewięć twierdzeń, każde sprawdzone względem zewnętrznej lub metodyczno-konwencjonalnej kotwicy. Trzy z nich (twierdzenia 6, 7 i 9) opierają się na pozycji własnej, a nie na wyniku badań. Te trzy są otwarcie bronione w sekcji steel-man na początku artykułu, nie udowodnione zewnętrznie, i to należy do logiki protokołu: pozycja własna może się pojawić, dopóki jest oznaczona jako taka i wystawiona na kontrpozycję.
Samoaudyt nie ma tu zadania ładnie wyglądać. Pokazuje na konkretnym przykładzie, co centralne twierdzenie artykułu znaczy w praktyce: że protokół ten jest faktycznie stosowany przed każdą z naszych publikacji, a nie tylko w niej opisany.
5 · Protokół na odwrót, jako narzędzie dla nabywców AI
Siedem kroków działa w ocenie dostawcy tak samo dobrze jak we własnej pracy redakcyjnej. Kto odpowiada w funkcji zakupowej, ryzyka lub zrównoważonego rozwoju, może zastosować następujące siedem pytań jako szablon oceny wobec dostawcy AI, zanim budżet PoC zostanie zwolniony:
- Jakie twierdzenia atomowe zawiera pitch dostawcy, dosłownie, nie poskładane z ciągłego tekstu?
- Jaki typ ma każde z tych twierdzeń (T1 do T7 z tabeli powyżej)?
- Jaka kotwica zewnętrzna jest podana na twierdzenie i czy leży na Tier 1, 2, 3 czy 4?
- Jaki pakiet odtwarzalności jest dołączony? Kod, seed, znacznik wersji danych?
- Jaki argument steel-man przeciw własnemu rozwiązaniu dostawca formułuje otwarcie?
- Jaka sekcja ograniczeń jest zawarta w dokumentach?
- Kto niezależnie zrecenzował model i gdzie ta recenzja jest udokumentowana?
Jeśli cztery lub więcej z tych pytań pozostaje bez pisemnie udokumentowanej odpowiedzi, dostawca nie jest w pozycji, w której PoC tworzy wiarygodną podstawę decyzji. Niepowodzenie nie jest przez to gwarantowane. Prawdopodobieństwo, w której z dwóch kohort MIT NANDA ostatecznie wylądujesz, da się jednak z tego wywnioskować z pewną dozą pewności.
6 · Czego ten artykuł nie robi
- Nie jest recenzowanym wkładem metodycznym. Jest pozycją, wspartą uznaną literaturą metodyczną. Kto szuka rzetelnego artykułu metodycznego o p-wartościach, czyta wprost Wasserstein/Lazar 2016.
- Nie gwarantuje sukcesu PoC. Obniża jedynie prawdopodobieństwo typowego trybu awarii widocznego w liczbach NANDA.
- Nie jest specyficzny dla surowca ani branży. Konkretne zastosowanie do pytań commodity-intelligence czy compliance łańcucha dostaw wymaga dodatkowych kotwic dziedzinowych, omawianych w kolejnych artykułach.
- Jest metodycznie konserwatywny. Kto chce szybszego workflow, nie znajdzie tu nic nowego. Kto chce wiedzieć, dlaczego celowo publikujemy wolno, znajdzie tu powód.
7 · Lista lektur i repozytorium towarzyszące
Lista lektur (siedem źródeł, w tej kolejności):
- Wasserstein & Lazar (2016) „The ASA Statement on p-Values” The American Statistician.
- Gelman & Loken (2014) „The Garden of Forking Paths” American Scientist.
- Ioannidis (2005) „Why Most Published Research Findings Are False” PLoS Medicine.
- Hansen, Lunde & Nason (2011) „The Model Confidence Set” Econometrica.
- Slack i in. (2020) „Fooling LIME and SHAP” arXiv 1911.02508.
- MIT NANDA (2025) „State of AI in Business 2025” (relacja prasowa Fortune 18 sierpnia 2025).
- Gartner (29.07.2024) Predicts 30 % of Generative AI Projects Will Be Abandoned After Proof of Concept by End of 2025.
Repozytorium towarzyszące:
github.com/myBytesResearch/truth-check-template.
Zawiera szablony dla claim-map, anchor-mapping i reproducibility-bundle, notatnik demo odtwarzający claim-map
tego artykułu oraz plik CITATION.cff dla cytowalności. CC BY 4.0 dla treści, MIT dla przykładów
kodu. Forki i pull requesty mile widziane. Protokół jest wyraźnie nie wewnętrznym aktywem myBytes, lecz naszym
zaproszeniem dla wspólnoty praktyki.
Zakończenie
Protokół powstał nie z metodycznego upodobania, lecz z konkretnych błędów, które popełniliśmy we własnych szkicach, zanim zostały opublikowane. Każdy z siedmiu kroków ma taki błąd na oku. Kto je czyta, widzi więc mniej ideologię metodyczną, a bardziej zobowiązanie wobec samych siebie. Protokół nie odfiltrowuje konkurencji, lecz nasz własny pośpiech.
Jeśli zechcesz przejąć, dostosować lub skrytykować protokół do własnej pracy, cieszy nas to. Repozytorium towarzyszące jest na to otwarte. A jeśli weźmiesz za złe któreś z postawionych tu twierdzeń, bo nie wytrzymuje kontroli według reguł protokołu, to jest dokładnie ten zarzut, na który ten artykuł zasługuje.