Forschungsmethodik
Ein Truth-Check-Protokoll für AI-Forschungs-Output
Wie wir bei myBytes nichts veröffentlichen, das wir nicht verteidigen können
Im August 2025 veröffentlichte das MIT NANDA-Programm den Bericht State of AI in Business 2025. Eine Zahl ging durch die Wirtschaftspresse: Trotz 30 bis 40 Milliarden US-Dollar an Unternehmens-Ausgaben für generative AI sehen 95 % der Organisationen keinen messbaren P&L-Effekt. Nur 5 % der Pilotprojekte erreichen die versprochene Umsatzbeschleunigung. Methodisch gestützt durch 150 Leadership-Interviews, eine 350-Personen-Umfrage und die Auswertung von 300 öffentlich dokumentierten AI-Deployments (Fortune, 18.08.2025).
Ein Jahr früher, am 29. Juli 2024, hatte Gartner prognostiziert: mindestens 30 % aller GenAI-Projekte werden bis Ende 2025 nach dem Proof of Concept abgebrochen, wegen schlechter Datenqualität, fehlender Risikokontrollen, eskalierender Kosten oder unklarem Business Value (Gartner Pressemitteilung).
Die beiden Erhebungen arbeiten mit unterschiedlichen Definitionen, einmal Abandonment, einmal No Return, und kommen aus unterschiedlichen methodischen Ecken. Ökonomisch betrachtet laufen sie auf denselben Befund hinaus: Wer als Einkäufer mit angewandter KI in Kontakt kommt, trifft am häufigsten auf ein Projekt, das scheitert. Daraus folgen Effekte, die sich in jedem Anbieter-Gespräch und in jeder Vorstandsdiskussion zeigen. Vorstände sind zurückhaltender geworden, Procurement-Abteilungen verlangen schriftliche Belege statt Folien-Versprechen, und seriöse Anbieter werden in denselben Vertrauenstrichter gezogen wie unseriöse. Der Grund liegt nicht bei den Modellen, sondern davor: In der Branche fehlt ein gemeinsames Protokoll dafür, was als verteidigbare KI-Behauptung gelten darf und was Marketing-Output bleibt.
Wir haben uns bei myBytes entschieden, ein solches Protokoll erst einmal für uns selbst zu schreiben, also vor und nicht nach der Veröffentlichung. Der vorliegende Artikel ist dieses Protokoll. Er beschreibt sieben Schritte, die jede unserer Forschungsveröffentlichungen durchläuft, und wendet sie auf den Text, den Sie gerade lesen, an.
1 · Warum die meisten KI-Behauptungen vor dem Audit fallen
Die Misserfolgsraten aus dem Lead sind aus unserer Sicht kein Modell-Problem, sondern ein Problem der Claim-Validation: Behauptungen werden in den Markt entlassen, ohne dass sie vor der Veröffentlichung gegen einen festen methodischen Maßstab geprüft worden wären.
Aus den experimentellen Wissenschaften ist seit Jahren bekannt, wie schnell aus unverbindlicher Forschungsfreiheit Befunde entstehen, die in der Replikation auseinanderfallen. John Ioannidis zeigte 2005 in PLoS Medicine, dass die Mehrheit publizierter Forschungsbefunde in der Replikation nicht bestätigt wird, ein Befund, der die sogenannte Replication Crisis ausgelöst hat (Ioannidis 2005). Andrew Gelman und Eric Loken prägten 2014 den Begriff Garden of Forking Paths: Selbst ohne vorsätzliches p-Hacking entstehen scheinbar signifikante Ergebnisse, sobald Forschende viele plausible Analyse-Entscheidungen nachträglich aus den Daten ableiten (Gelman & Loken 2014). Und die American Statistical Association hat 2016 mit ihrem Statement on p-Values die Praxis der Schwellenwert-Interpretation ausdrücklich kritisiert (Wasserstein & Lazar 2016, The American Statistician).
In angewandter KI treffen diese Muster auf zwei zusätzliche Treiber, die das Risiko verstärken:
- Hyperparameter-Suche und Modellauswahl ohne Konsistenz-Test. Wer aus 13 Modellen das „beste“ Backtest-Modell wählt, kalibriert nicht, er sucht. Ohne Verfahren wie den Model Confidence Set von Hansen, Lunde und Nason (2011, Econometrica) ist die Auswahl nicht gegen Mehrfach-Vergleichs-Inflation geschützt.
- Erklärbarkeit-Theater. SHAP-Plots werden als Beweis kausaler Mechanismen präsentiert, obwohl sie messen, was das Modell tut, nicht, was die Welt tut. Slack und Kollegen haben 2020 gezeigt, wie leicht gerade SHAP und LIME manipulierbar sind (Slack et al. 2020).
In der Folge entstehen PoC-Präsentationen, die im internen Backtest beeindrucken und in der Produktion auseinanderfallen. Die Modelle selbst sind dabei selten falsch. Was fehlt, ist eine vorgelagerte Prüfung der Behauptungen über die Modelle. Genau diese Lücke quantifizieren die beiden Studien aus dem Lead: die MIT-NANDA-Auswertung auf der Wirkungsebene und die Gartner-Prognose auf der Projektabbruch-Ebene.
2 · Die sieben Schritte des myBytes Truth-Check-Protokolls
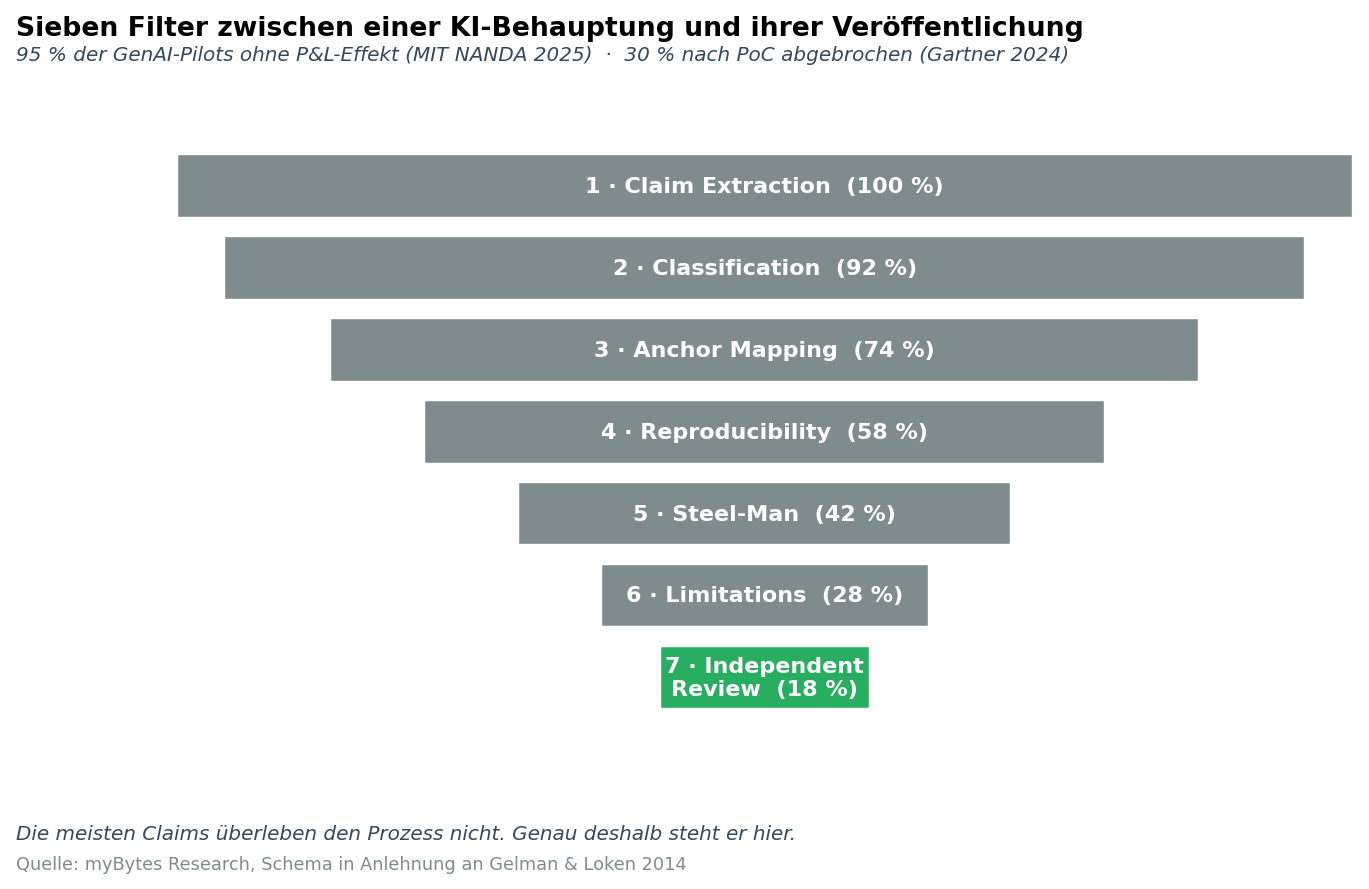
Das Protokoll besteht aus sieben Schritten, die nacheinander durchlaufen werden. Kein Schritt darf übersprungen werden, weil jeder gegen eine andere Fehlerquelle gerichtet ist.
2.1 Claim Extraction - was wird im Artikel eigentlich behauptet
Jeder Artikel-Entwurf wird in atomare Behauptungen zerlegt. Atomar heißt: ein einzelner überprüfbarer Satz. „Unser Modell schlägt die Baseline“ ist keine atomare Behauptung, es enthält drei: welches Modell, welche Baseline, welche Metrik. Erst nach der Zerlegung ist sichtbar, was tatsächlich zu verteidigen ist und was nur rhetorische Verbindung darstellt.
Fehlerfall, den dieser Schritt abfängt: Aussagen, die im Fließtext plausibel klingen, aber bei wörtlicher Prüfung zwei oder drei nicht zusammenpassende Teilaussagen enthalten.
2.2 Claim Classification - der Typ der Behauptung
Wir klassifizieren jeden atomaren Claim in einen von sieben Typen. Die Typologie steuert, welche Art von Beweis ausreicht:
| Typ | Beispiel | Was reicht nicht |
|---|---|---|
| T1 Stylized Fact | „Cocoa-Returns haben Kurtosis ≈ 7“ | eigene Berechnung allein |
| T2 Methoden-Vergleich | „GJR-GARCH-t schlägt EGARCH auf KC=F“ | Bestenauswahl aus vielen Modellen |
| T3 Kausal / Ökonomisch | „Hafenankünfte führen den Preis“ | Korrelation oder Granger allein |
| T4 Prognose-Güte | „AUC 0,71, Vorlauf 5-7 Wo“ | ein Backtest |
| T5 Regulatorisch / Legal | „EUDR-Stichtag 30.12.2026 (Großbetriebe)“ | Sekundärquelle |
| T6 Remote Sensing | „NDVI-Anomalie ≥ 3σ ⇒ Crop-Loss“ | Korrelation in 1 Saison |
| T7 Marktmechanismus | „Spekulation trieb Cocoa 2024“ | Narrative |
Fehlerfall, den dieser Schritt abfängt: Eine Kausalbehauptung mit dem Beweis-Standard einer deskriptiven Statistik zu untermauern.
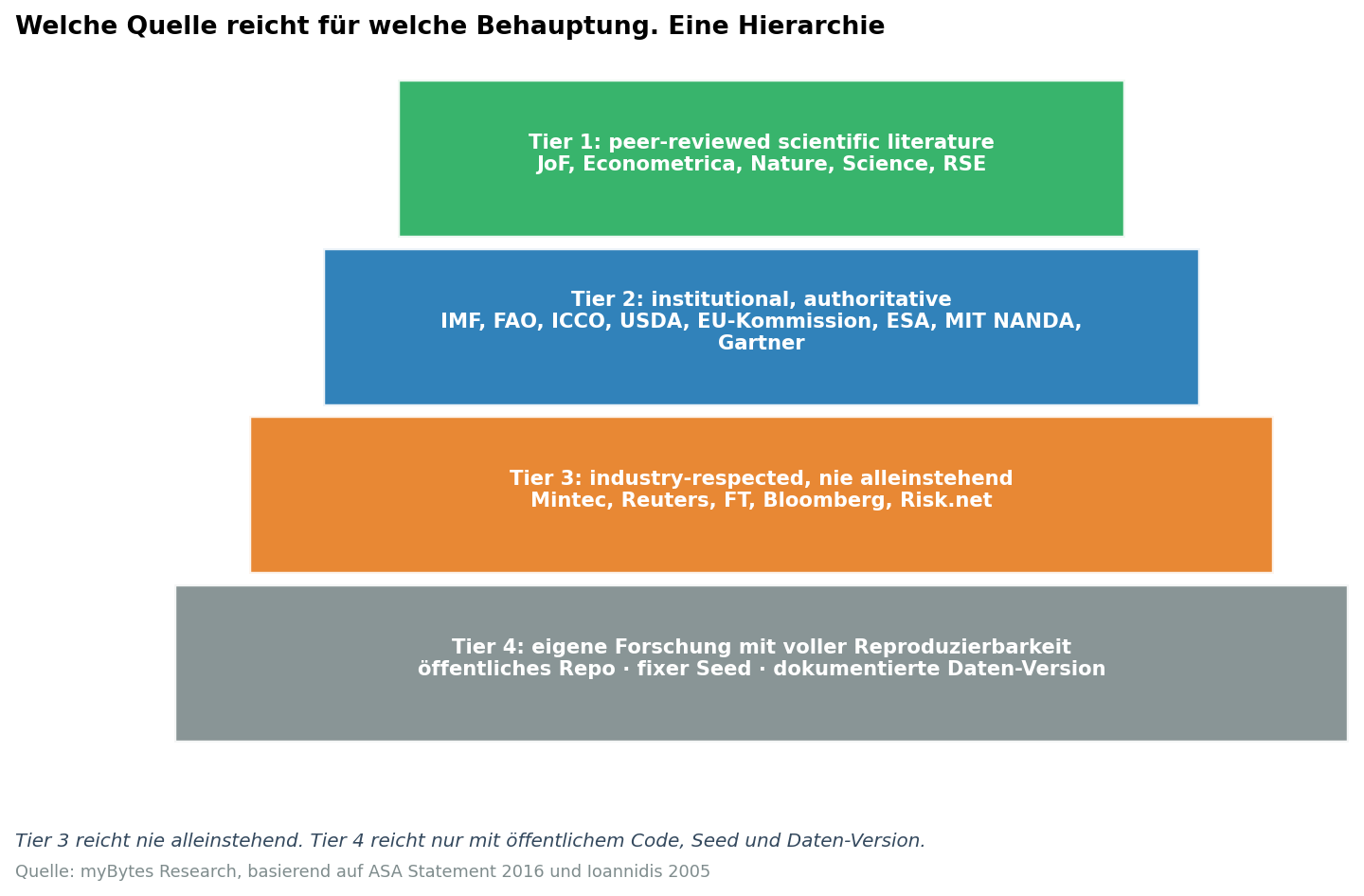
2.3 Anchor Mapping - der externe Beleg
Jeder atomare Claim braucht mindestens einen externen Anker aus einer definierten Hierarchie. Wir unterscheiden vier Tiers:
- Tier 1, peer-reviewed: Journal of Financial Economics, Journal of Finance, Econometrica, Remote Sensing of Environment, Nature, Science, Journal of Commodity Markets, Climatic Change; SSRN und arXiv als Working Papers mit explizitem Caveat.
- Tier 2, institutionell autoritativ: IMF, Weltbank, FAO, IFPRI, ICCO, USDA-FAS, EUROSTAT, EU-Kommission, ESA, NOAA, NASA, JRC, Wageningen UR, MIT (z. B. NANDA, CSAIL, MIT Sloan), Gartner-Research.
- Tier 3. Industrie, respektiert, aber nie alleinstehend: Mintec, S&P Global Commodity Insights, Argus, Reuters Commodities, FT, Bloomberg, Risk.net.
- Tier 4, eigene Forschung mit voller Reproduzierbarkeit: öffentliches Repository, fixe Seeds, dokumentierte Datenversionen, Lizenz-konform.
Eine T3- oder T7-Behauptung akzeptieren wir nie mit Tier-3 alleinstehend. Eine T1-Behauptung akzeptieren wir nie mit Tier-4 alleinstehend.
Fehlerfall, den dieser Schritt abfängt: Anbieter-Whitepaper als einzige Quelle für eine Behauptung, die durch peer-reviewed Forschung abgedeckt ist.
2.4 Reproducibility Bundle - kann jemand die Aussage nachrechnen
Für jeden numerischen Befund liegt zum Zeitpunkt der Veröffentlichung ein reproduzierbares Bundle bereit:
Quellcode mit fixiertem Seed, Datenquelle mit Versionsstempel, Library-Versionen gepinnt, eine
CITATION.cff für Zitierfähigkeit. Ist die Datenquelle proprietär, dokumentieren wir den Bezug
öffentlich (Lizenz, Bezugsweg) und stellen einen anonymisierten Demo-Datensatz bereit, auf dem dieselbe
Auswertung läuft.
Fehlerfall, den dieser Schritt abfängt: Numerische Behauptungen, die sechs Monate nach Veröffentlichung niemand mehr rekonstruieren kann, auch nicht die Autorinnen und Autoren selbst.
2.5 Steel-Man Counter-Argument - der schärfste Einwand
Vor der Veröffentlichung wird die stärkste denkbare Gegenposition explizit formuliert. Nicht ein Strohmann. Ein Steel-Man: das beste Argument der anderen Seite, fair rekonstruiert. Wir greifen dieses Argument im Fließtext auf, nicht in einer Fußnote.
Fehlerfall, den dieser Schritt abfängt: Artikel, die nur funktionieren, solange ein freundlich gesinnter Leser sie liest.
2.6 Limitations - die Bedingungen, unter denen die Aussage nicht gilt
Pflicht-Sektion am Ende jedes Artikels. Sensorlimitierung, Datenfenster, Sample-Selection, Survivorship-Bias, Domain-Übertragbarkeit. Wir benennen nicht alle denkbaren Limitationen. Sondern die drei bis fünf, die ein sachkundiger Leser tatsächlich aktiv prüfen würde.
Fehlerfall, den dieser Schritt abfängt: Artikel, deren Aussagen ohne explizite Gültigkeitsgrenzen in fremden Kontexten zitiert werden, in denen sie nicht halten.
2.7 Independent Review - die Gegenprüfung außerhalb der Schreibgruppe
Eine Person, die nicht am ursprünglichen Entwurf beteiligt war, prüft den Artikel gegen die Schritte 1 bis 6 und zeichnet das Ergebnis. Diese Person ist namentlich genannt. Der Review wird dokumentiert.
Fehlerfall, den dieser Schritt abfängt: Blinde Flecken der eigenen Schreibgruppe.
3 · Was gegen unser eigenes Protokoll spricht
Der ehrliche Steel-Man gegen uns selbst:
„Sieben Schritte erzeugen Bürokratie. Sie senken die Veröffentlichungs-Geschwindigkeit und filtern Innovation heraus, die in unsicheren Behauptungen schlummert. Falsifikations-Disziplin gegenüber dem eigenen Output ist nicht für jedes Veröffentlichungsformat angemessen, ein LinkedIn-Post mit einer Hypothese braucht keinen Review-Prozess wie ein peer-reviewed Paper.“
Der Einwand ist berechtigt, und er hat unsere Anwendung des Protokolls verändert. In der Praxis skaliert das Protokoll mit dem publikatorischen Verbindlichkeitsgrad einer Veröffentlichung. Ein Hypothesen-Post auf LinkedIn durchläuft bei uns nur die Schritte 1, 2 und 6. Eine Research Note für die Website durchläuft alle sieben. Ein internes Diskussionspapier durchläuft keinen davon. Was wir aber nie zulassen, unabhängig vom Kanal: dass ein Befund mit numerischer Aussage ohne Schritt 3 und 4 in einen veröffentlichten Text gelangt.
Die Veröffentlichungs-Geschwindigkeit sinkt durch diese Disziplin spürbar. Diese Verlangsamung ist die beabsichtigte Wirkung, nicht ein Kollateralschaden der Methodik.
4 · Das Protokoll, auf diesen Artikel angewendet
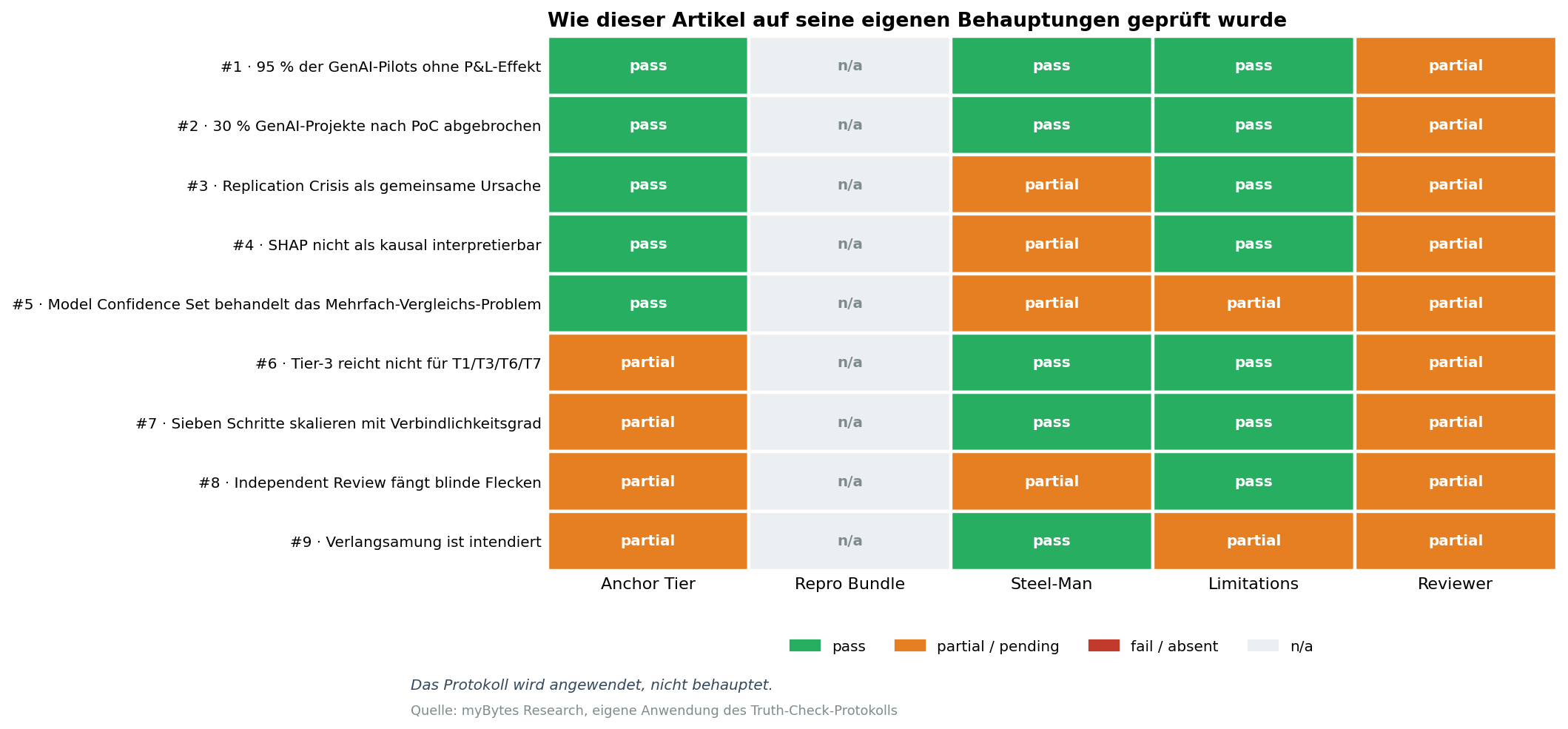
Auswahl der zentralen Claims dieses Artikels und ihr Status:
| # | Behauptung | T-Typ | Anker | Bundle | Steel-Man | Limits |
|---|---|---|---|---|---|---|
| 1 | „95 % der GenAI-Pilotprojekte ohne P&L-Effekt“ | T2 | MIT NANDA 2025 via Fortune | n/a | behandelt | dokumentiert |
| 2 | „30 % GenAI-Projekte nach PoC abgebrochen“ | T2 | Gartner 2024 PR | n/a | behandelt | dokumentiert |
| 3 | „Replication Crisis hat methodische Ursachen“ | T1 | Ioannidis 2005; Gelman/Loken 2014 | n/a | - | dokumentiert |
| 4 | „SHAP nicht als kausal interpretierbar“ | T2 | Slack et al. 2020 | n/a | - | dokumentiert |
| 5 | „Model Confidence Set behandelt das Mehrfach-Vergleichs-Problem“ | T2 | Hansen/Lunde/Nason 2011 | n/a | - | - |
| 6 | „Tier-3 reicht nicht für T1/T3/T6/T7“ | T7 | eigene Konvention | n/a | behandelt | dokumentiert |
| 7 | „Sieben Schritte skalieren mit Verbindlichkeitsgrad“ | T7 | eigene Konvention | n/a | behandelt | dokumentiert |
| 8 | „Independent Review fängt blinde Flecken“ | T7 | Methodologie-Common-Sense | n/a | - | dokumentiert |
| 9 | „Verlangsamung ist intendiert“ | T7 | eigene Position | n/a | behandelt | - |
Insgesamt neun Claims, jeweils gegen einen externen oder methodisch-konventionellen Anker geprüft. Drei davon (Claims 6, 7 und 9) stützen sich auf eine eigene Position statt auf einen Forschungsbefund. Diese drei sind im Steel-Man-Abschnitt zu Beginn dieses Artikels offen verteidigt, nicht extern belegt, und das gehört zur Logik des Protokolls: Eine eigene Position darf vorkommen, solange sie als solche markiert und einer Gegenposition ausgesetzt ist.
Der Selbst-Audit hat hier keine Aufgabe, hübsch auszusehen. Er zeigt am konkreten Beispiel, was die zentrale Behauptung des Artikels in der Praxis bedeutet: dass dieses Protokoll vor jeder unserer Veröffentlichungen tatsächlich angewendet wird, nicht nur in ihr beschrieben.
5 · Das Protokoll umgekehrt, als Werkzeug für Käufer von KI
Die sieben Schritte funktionieren bei der Anbieter-Bewertung genauso gut wie in der eigenen Redaktionsarbeit. Wer in einer Procurement-, Risk- oder Sustainability-Funktion verantwortlich ist, kann die folgenden sieben Fragen als Bewertungs-Raster gegen einen KI-Anbieter anlegen, bevor PoC-Budget freigegeben wird:
- Welche atomaren Behauptungen enthält der Pitch des Anbieters, wörtlich, nicht aus dem Fließtext zusammengelesen?
- Welchen Typ hat jede dieser Behauptungen (T1 bis T7 aus der Tabelle oben)?
- Welcher externe Anker wird pro Behauptung genannt, und liegt er auf Tier 1, 2, 3 oder 4?
- Welches Reproducibility Bundle liegt bei? Code, Seed, Daten-Versionsstempel?
- Welches Steel-Man-Argument gegen die eigene Lösung spricht der Anbieter offen aus?
- Welche Limitations-Sektion ist in den Unterlagen enthalten?
- Wer hat das Modell unabhängig reviewt, und wo ist dieser Review dokumentiert?
Bleiben vier oder mehr dieser Fragen ohne schriftlich belegte Antwort, ist der Anbieter nicht in einer Position, in der ein PoC eine belastbare Entscheidungsgrundlage produziert. Ein Misserfolg ist damit nicht garantiert. Die Wahrscheinlichkeit, in welcher der zwei MIT-NANDA-Kohorten Sie am Ende landen werden, lässt sich daraus aber mit einiger Sicherheit ableiten.
6 · Was dieser Artikel nicht leistet
- Er ist kein peer-reviewed Methodenbeitrag. Er ist eine Position, gestützt auf etablierte Methodik-Literatur. Wer ein fundiertes Methodenpapier zu p-Werten sucht, liest Wasserstein/Lazar 2016 direkt.
- Er garantiert keinen PoC-Erfolg. Er senkt nur die Wahrscheinlichkeit des typischen Fehlerfall, der in den NANDA-Zahlen sichtbar wird.
- Er ist nicht commodity-spezifisch oder branchen-spezifisch. Die konkrete Anwendung auf Commodity-Intelligence- oder Supply-Chain-Compliance-Fragen verlangt zusätzliche fachliche Anker, die in Folgeartikeln behandelt werden.
- Er ist methodisch konservativ. Wer einen schnelleren Workflow möchte, findet hier nichts Neues. Wer wissen will, warum wir absichtlich langsam publizieren, findet hier den Grund.
7 · Reading List & Companion Repository
Reading List (sieben Quellen, in dieser Reihenfolge):
- Wasserstein & Lazar (2016) „The ASA Statement on p-Values“ The American Statistician.
- Gelman & Loken (2014) „The Garden of Forking Paths“ American Scientist.
- Ioannidis (2005) „Why Most Published Research Findings Are False“ PLoS Medicine.
- Hansen, Lunde & Nason (2011) „The Model Confidence Set“ Econometrica.
- Slack et al. (2020) „Fooling LIME and SHAP“ arXiv 1911.02508.
- MIT NANDA (2025) „State of AI in Business 2025“ (Pressedarstellung Fortune 18.08.2025).
- Gartner (29.07.2024) Predicts 30 % of Generative AI Projects Will Be Abandoned After Proof of Concept by End of 2025.
Companion Repository:
github.com/myBytesResearch/truth-check-template.
Enthält die Templates für Claim-Map, Anchor-Mapping und Reproducibility-Bundle, ein Demo-Notebook, das die
Claim-Map dieses Artikels reproduziert, sowie eine CITATION.cff für die Zitierfähigkeit.
CC BY 4.0 für Inhalt, MIT für Code-Beispiele. Forks und Pull Requests willkommen. Das Protokoll ist explizit
kein myBytes-internes Asset, sondern unsere Einladung an die Praxisgemeinschaft.
Schluss
Das Protokoll ist nicht aus einer methodischen Vorliebe entstanden, sondern aus konkreten Fehlern, die wir in unseren eigenen Entwürfen gemacht haben, bevor diese veröffentlicht wurden. Jeder der sieben Schritte hat einen solchen Fehler im Blick. Wer sie liest, sieht deshalb weniger eine methodische Ideologie als eine Selbstverpflichtung. Das Protokoll filtert nicht die Konkurrenz aus, sondern unsere eigene Eile.
Sollten Sie das Protokoll für die eigene Arbeit übernehmen, anpassen oder kritisieren wollen, freut uns das. Das Companion Repository steht dafür offen. Und sollten Sie an einer der hier formulierten Behauptungen Anstoß nehmen, weil sie der Prüfung nach den Regeln des Protokolls nicht standhält, ist das genau der Einwand, den dieser Artikel verdient.